DeerFlow 2.0 Isn't a Framework — It's a Harness
ByteDance open-sourced DeerFlow 2.0 and it hit #1 on GitHub Trending in hours. The number isn't the story. The shift from framework to batteries-included harness is.
DeerFlow 2.0, ByteDance’s open-source agent project, hit #1 on GitHub Trending within hours of shipping.
That number is the headline. It isn’t the story.
Trending charts reward novelty and a big name. What’s worth your attention is the category DeerFlow 2.0 is shipping in: it’s a ground-up rewrite that hands any LLM a filesystem, persistent memory, sandboxed execution, and the ability to spawn sub-agents — MIT-licensed and model-agnostic. Not a library you assemble into an agent. A harness you drop a model into.
That distinction is the whole point.
Framework vs. Harness
A framework hands you primitives. You get building blocks — a way to call tools, a way to loop, maybe a graph abstraction — and the wiring is your job. You decide how memory persists, where code runs, how one agent hands work to another, and how the whole thing recovers when a step fails. That flexibility is real, and for some teams it’s the right trade. But it means every project starts by rebuilding the same scaffolding.
A harness ships that scaffolding pre-assembled. The filesystem, the memory, the execution sandbox, the sub-agent machinery — they’re already there and already wired together. You bring a model; the harness gives it an environment to act in. The work moves from “build the agent” to “use the agent.”
Calling something “batteries-included” is easy. What makes DeerFlow’s version concrete is exactly which batteries are in the box.
The Four Batteries
Any LLM plugged into DeerFlow 2.0 gets four capabilities out of the box:
- A filesystem. It can read and write real files, not just pass strings around in a context window. State that outlives a single turn lives on disk.
- Memory. Information persists across steps, so the agent isn’t re-deriving what it already figured out three actions ago.
- Sandboxed execution. It can run actual code — install a dependency, hit an API, parse the output — inside an isolated environment instead of pretending to in text.
- Sub-agents. It can spawn workers on demand and delegate, rather than carrying every sub-task in one increasingly crowded conversation.
The first three are table stakes for any serious agent runtime. The fourth is where the architecture gets interesting.
The Mechanic That Matters: Sub-Agent Fan-Out
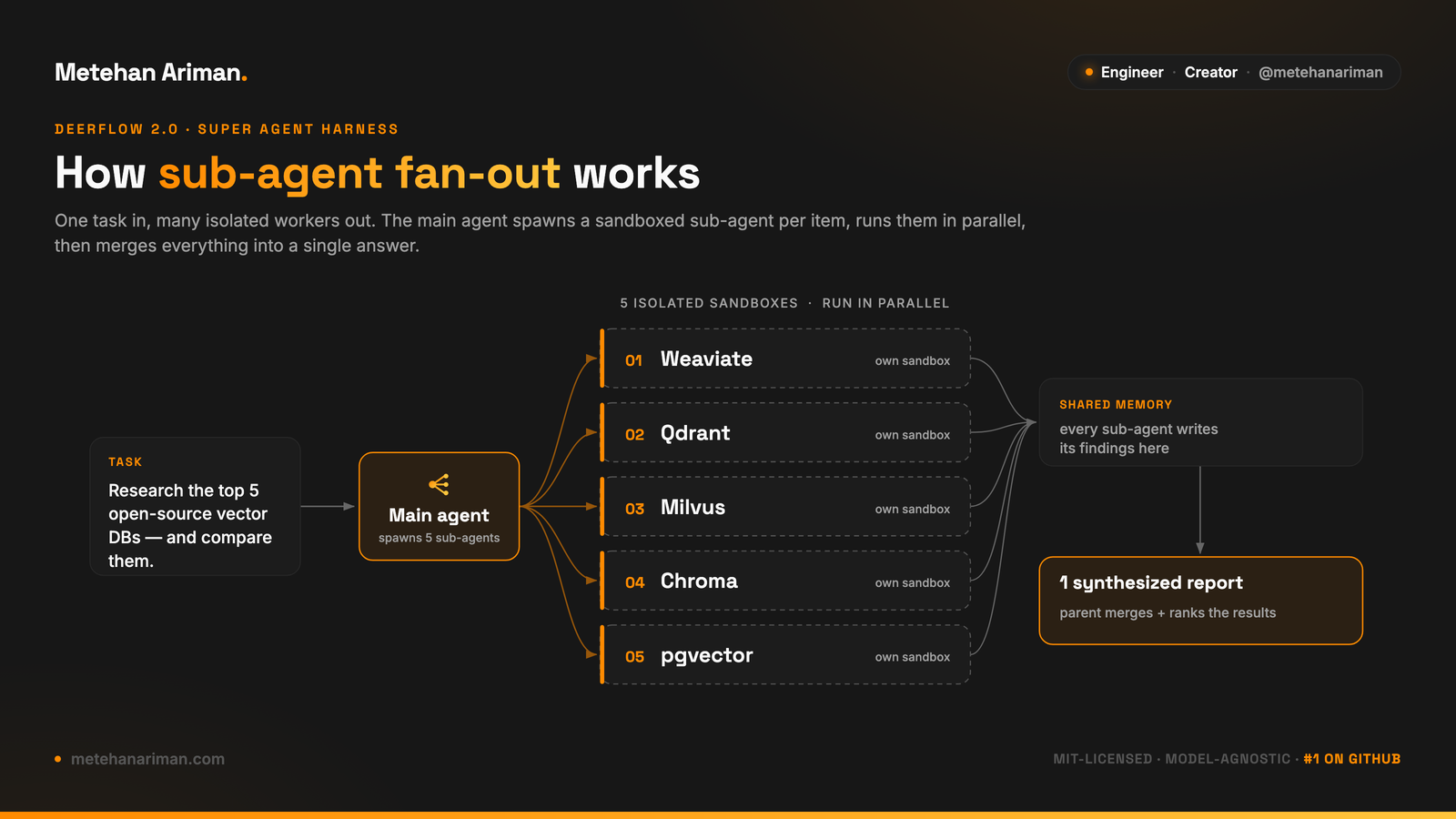
Here’s the model in one task.
You ask: “Research the top five open-source vector databases and compare them.”
A single-context agent would work through this linearly — read about Weaviate, then Qdrant, then Milvus, then Chroma, then pgvector — accumulating everything into one growing context window. By the fifth database, the window is full of five databases’ worth of detail, and the model is reasoning across a crowded, drifting context.
DeerFlow’s fan-out inverts that. The main agent spawns one sub-agent per database. Each runs in its own sandbox, gathers its own data in parallel, and writes its findings back to shared memory. The parent never holds all five raw research sessions at once — it reads the clean summaries and synthesizes a single ranked report.
Two things fall out of this design, and both matter more than the parallelism:
Isolation. Each sub-agent can run real code — install a client, query a benchmark, parse results — without touching your machine or polluting the other agents’ context. One sub-agent’s mess stays in its own sandbox. That’s what makes parallel execution safe instead of chaotic.
Clean context. The parent works with summaries, not transcripts. Instead of one window that fills up and loses focus as the task grows, you get many short-lived windows that each do one thing and report back. Context management stops being the thing that quietly degrades a long task.
The Honest Question
Here’s where I’d resist the trending chart.
Orchestration is not free. Spawning sub-agents, coordinating their sandboxes, and merging their output adds latency and moving parts. For a two-step task, a single focused session in Claude Code or Cursor will beat a fan-out every time — you’re paying coordination overhead to solve a problem that didn’t need coordinating.
The fan-out earns its keep when a task genuinely decomposes: five independent research threads, a dozen files to refactor in parallel, a batch of items that each need their own tool calls. The question isn’t whether the architecture is elegant. It’s whether your task is shaped like the problem this architecture solves.
So don’t take the #1 ranking as a verdict. Take it as a prompt to run the experiment.
Pick one real, multi-step task you actually care about. Run it through DeerFlow 2.0. Then run the same task by hand in a single Claude Code or Cursor session. Compare the wall-clock time, the quality of the result, and how much babysitting each one needed.
If orchestration saved you time, you’ve found a tool for a class of work you do often. If it just added overhead, you’ve learned something more useful than any benchmark: that for the way you work, a focused single session is still the thing to beat.
That’s the only review that counts — the one you run yourself.